DeCo Overview
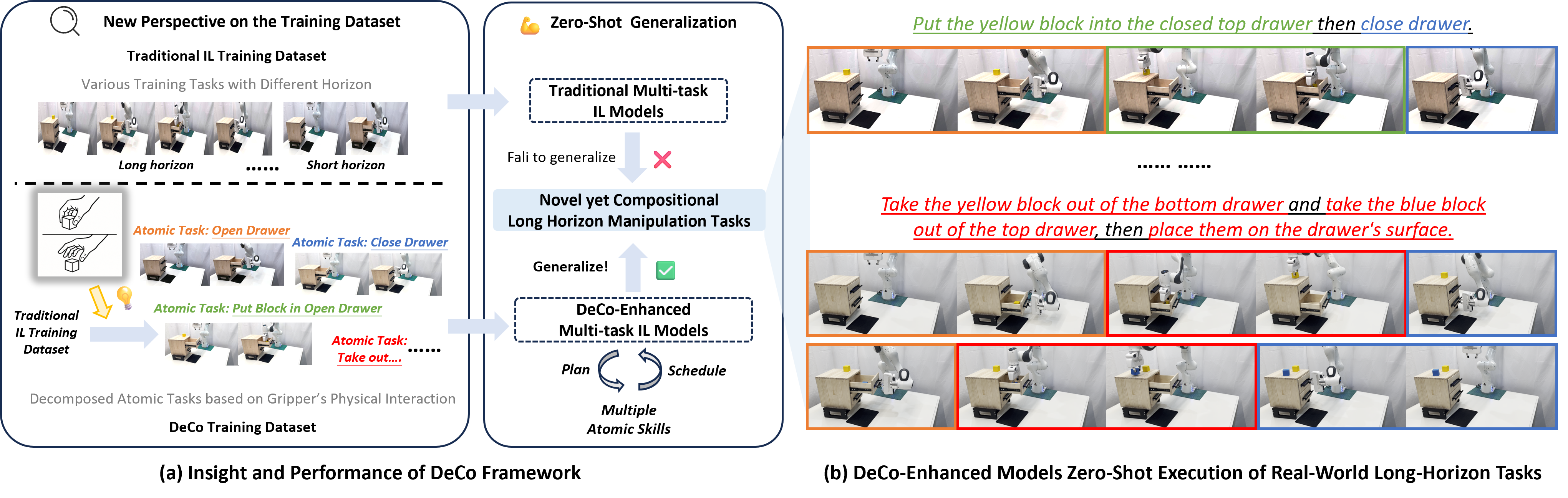
We introduce DeCo, a model-agnostic framework that enables multi-task imitation learning models to generalize zero-shot to novel long-horizon 3D manipulation tasks by retrieving, scheduling, and chaining atomic skills.
Full and half interactions

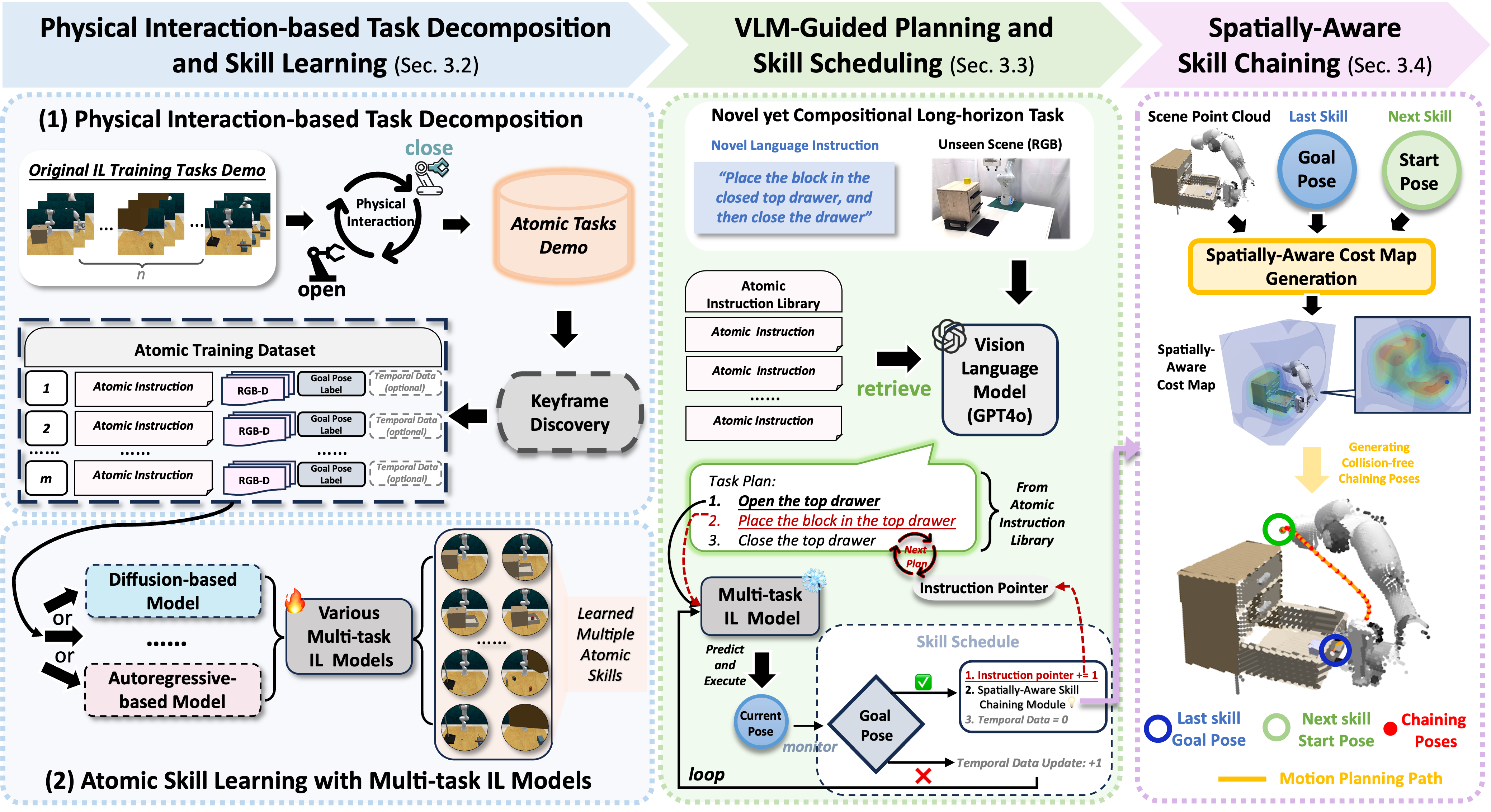
Method overview
DeCo Performance on 12 Novel Tasks (36 variations)
Failure Analysis
The ability of the base multi-task IL model to learn atomic skills is crucial for DeCo's generalization performance in long-horizon tasks. However, the model's generalization capability relies not only on its learning of atomic skills but also on other factors. Visual robustness is a key factor: different models have varying levels of visual robustness when confronted with previously unseen combinations in scenarios. If the base multi-task IL model's visual capability cannot effectively handle these variations, it will directly impact DeCo's ability to generalize in multi-task IL models when handling combined long-horizon tasks. We provide visual failure cases of 3DDA+DeCo and ARP+DeCo to further illustrate this limitation. Although 3DDA+DeCo and ARP+DeCo excel in learning atomic tasks, they encounter failures when facing the compositional long-horizon tasks Sweep and Drop (sweep rubbish + drop rubbish) and Retrieve and Sweep (broom out of cupboard + sweep rubbish). Even though DeCo can plan and schedule the corresponding atomic skills, both 3DDA and ARP struggle with visual processing in unseen combination scenarios. As a result, 3DDA+DeCo and ARP+DeCo fail to execute the atomic skills, which prevents them from completing the entire long-horizon tasks.
DeCo Performance on 9 Novel Real-world Tasks (30 variations)
put the yellow block in the bottom drawer. (success)
Real-world Task Execution Monitoring under Manually Induced Perturbations
In Fail
In Success
Out Fail
Out Success
Prompts
Prompts in Simulation Environments:
Prompt Examples (full) |
Prompt Examples (half)
BibTeX
@article{chen2025deco,
title={DeCo: Task decomposition and skill composition for zero-shot generalization in long-horizon 3D manipulation},
author={Chen, Zixuan and Yin, Junhui and Chen, Yangtao and Huo, Jing and Tian, Pinzhuo and Shi, Jieqi and Hou, Yiwen and Li, Yinchuan and Gao, Yang},
journal={arXiv preprint arXiv:2505.00527},
year={2025}
}